





摘要:,,本文探讨了凤凰网新闻爬虫的设计与应用的探讨。文章介绍了新闻爬虫的基本概念和工作原理,分析了凤凰网新闻爬虫的设计要点,包括数据抓取、数据存储、数据分析等方面。文章还探讨了新闻爬虫的应用场景,如数据挖掘、舆情分析、新闻报道等。文章总结了凤凰网新闻爬虫的应用价值和发展前景,强调了其在信息时代的重要性。
本文目录导读:
随着互联网技术的快速发展,新闻信息的获取和传播方式发生了深刻变革,新闻爬虫作为一种自动化获取网络新闻信息的技术手段,被广泛应用于新闻报道、舆情分析等领域,凤凰网作为国内知名的新闻网站,其新闻爬虫的设计对于提高新闻信息采集效率、优化用户体验具有重要意义,本文将探讨凤凰网新闻爬虫的设计思路、技术实现及面临的挑战。
凤凰网新闻爬虫的设计思路
1、需求分析
在设计凤凰网新闻爬虫之前,需对爬虫的应用场景、功能需求进行深入分析,需要爬取的新闻类型、数据来源、更新频率等,还需考虑用户对于新闻信息的需求,如实时性、准确性、多样性等。
2、技术路线选择
根据需求分析结果,选择合适的技术路线,采用基于网页爬虫技术,结合自然语言处理、机器学习等技术,实现对凤凰网新闻内容的自动化爬取、分析和处理。
3、爬虫架构设计
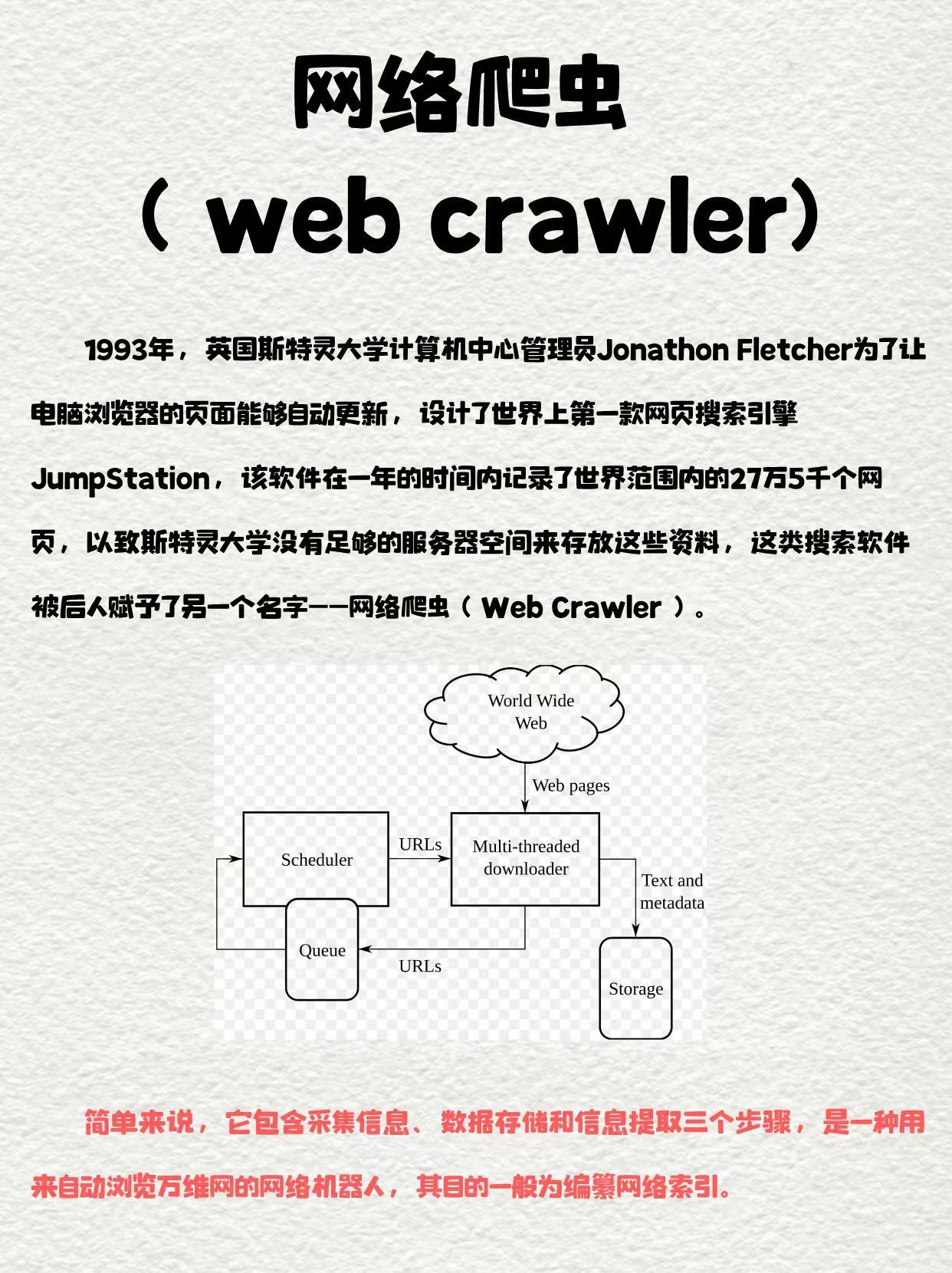
凤凰网新闻爬虫架构设计需考虑数据获取、数据处理、数据存储等方面,数据获取方面,需设计合适的网络爬虫算法,实现对凤凰网新闻页面的高效爬取,数据处理方面,需对爬取到的新闻数据进行清洗、去重、分类等操作,数据存储方面,需设计合理的数据库结构,实现对新闻数据的存储和管理。
凤凰网新闻爬虫的技术实现
1、数据获取
数据获取是新闻爬虫的核心环节,针对凤凰网的特点,可采用基于网页爬虫技术,结合多线程、分布式等技术,实现对凤凰网新闻页面的高效爬取,需关注网页反爬虫策略,采取相应措施应对网页动态加载、反爬虫机制等挑战。
2、数据处理
数据处理环节主要包括新闻数据的清洗、去重、分类等操作,针对凤凰网的新闻数据,可采用自然语言处理、机器学习等技术,实现对新闻标题、内容、来源等信息的自动提取和分类,还需对新闻数据进行情感分析、关键词提取等操作,以便为用户提供更加个性化的新闻推荐服务。

3、数据存储
数据存储环节需设计合理的数据库结构,实现对新闻数据的存储和管理,针对凤凰网新闻数据的特点,可采用关系型数据库与非关系型数据库相结合的方式,实现对海量新闻数据的存储和高效查询。
凤凰网新闻爬虫面临的挑战与对策
1、网页反爬虫策略
凤凰网等新闻网站为应对爬虫访问,采取了一系列反爬虫策略,如动态加载页面内容、使用验证码等,针对这些挑战,可通过分析网页结构、模拟用户行为等方式进行应对。
2、数据处理难度

随着新闻报道的多样化,新闻数据的处理难度逐渐增大,为提高数据处理效率,可结合自然语言处理、机器学习等技术,提高新闻数据的自动化处理水平。
3、法律法规遵守
在爬虫设计与应用过程中,需严格遵守相关法律法规,尊重网站版权和隐私保护,需关注网络爬虫对网站性能的影响,避免给目标网站带来不必要的负担。
凤凰网新闻爬虫的设计与应用对于提高新闻报道效率、优化用户体验具有重要意义,在设计过程中,需充分考虑需求分析、技术路线选择、架构设计等方面,面对挑战如网页反爬虫策略、数据处理难度等,需采取相应的对策进行应对,随着技术的不断发展,凤凰网新闻爬虫的应用将更加广泛,为新闻报道和舆情分析等领域带来更多便利和机遇。
 沪ICP备2021027615号-1
沪ICP备2021027615号-1 沪ICP备2021027615号-1
沪ICP备2021027615号-1
还没有评论,来说两句吧...